主要看是看Diffusion Models,CLIP,ControlNet,IP-Adapter这种经典论文,尝试总结论文写作的一些方式以及图像生成模型的一些内在思想. 对于其中的数学原理和代码不过深究.
DDPM
使用扩散模型得到高质量图像,证明了这种方法在训练时与多种噪声等级下的去噪分数等同,在采样时与退火朗文动力学等价.
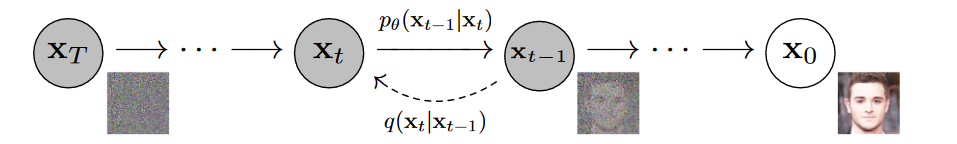
有forward precess和reversed process,

对于正向过程,就是对图像的一个加噪过程, 逆向过程需要通过神经网络拟合,论文中没有考虑方差.


使用了重参数化,类似VAE中的思想.在加噪声时,通过使用高斯噪声和均值、方差.
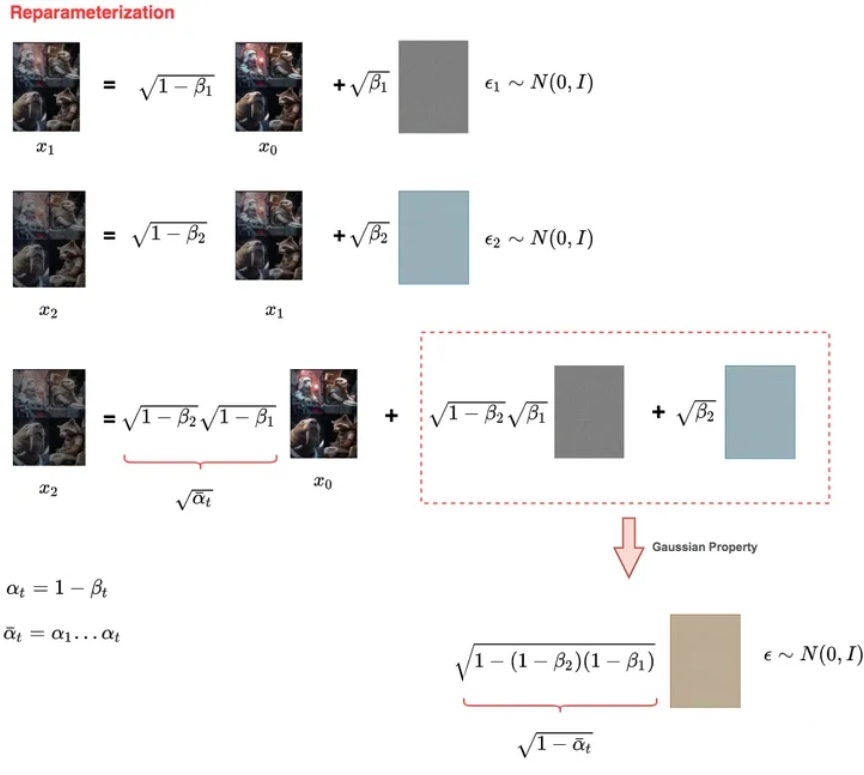
这样只要知道x_0以及超参数α和β就能得到后面加噪的数据.计算概率密度函数

对于优化目标,需要让p和q的分布尽量接近,相当于让均值和方差类似.
$$
\sum_{t=2}^TE_{q(x_t|x_0)}[D_{KL}(q(x_{t-1}|x_t,x_0)||p_\theta(x_{t-1}|x_t)]$$
而方差是定值,对于均值
$$
\begin{aligned}
\mu_{q}& =\frac{\sqrt{\bar{\alpha}{t-1}}\beta{t}x_{0}+\sqrt{\alpha_{t}}(1-\bar{\alpha}{t-1})x{t}}{1-\bar{\alpha}{t}} \ &=\frac{\sqrt{\bar{\alpha}{t-1}}\beta_{t}\frac{x_{t}-\sqrt{1-\bar{\alpha}{t}}\epsilon}{\sqrt{\bar{\alpha}{t}}}+\sqrt{\alpha_{t}}(1-\bar{\alpha}{t-1})x{t}}{1-\bar{\alpha}{t}} \ &=\frac{1}{\sqrt{\alpha{t}}}(x_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}}\epsilon)
\end{aligned}
$$
模型使用了Unet和attention,残差连接预测噪声.得到噪声后可以得到$p_\theta(x_{t-1}|x_t)$
$$
x_{t-1}=\frac{1}{\sqrt{\alpha_{t}}}(x_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}{t}}}\epsilon{\theta})+\sigma_{q}z
$$
论文http://arxiv.org/abs/2006.11239 深入浅出扩散模型(Diffusion Model)系列:基石DDPM(人人都能看懂的数学原理篇) - 知乎 (zhihu.com)
Improved DDPM
对DDPM做了改进.
- 学习方差会让生成效果更好(DDPM 中只学习了均值,方差是一个常数)
- 提出了余弦加噪方法,比线性加噪效果更好
DDIM 2020
为了加快采样速度,提出了去噪扩散隐含模型(DDIMs),这是一类更有效的迭代隐含概率模型,其训练过程与 DDPMs 相同。在 DDPMs 中,生成过程被定义为特定马尔可夫扩散过程的反向。
我们通过一类能实现相同训练目标的非马尔可夫扩散过程来推广 DDPM。这些非马尔可夫过程可以对应于确定性的生成过程,从而产生能更快地生成高质量样本的隐式模型。

关于 DDIM 采样算法的推导 | Ze's Blog (zeqiang-lai.github.io)
上面三个数学公式涉及比较多,比较偏学术,我的目的是想介绍一个脉络和抽象的概念和作用,使得使用一些开源AI绘画这类应用时更加得心应手,下面更多涉及到一些AI绘画功能层面上的东西.
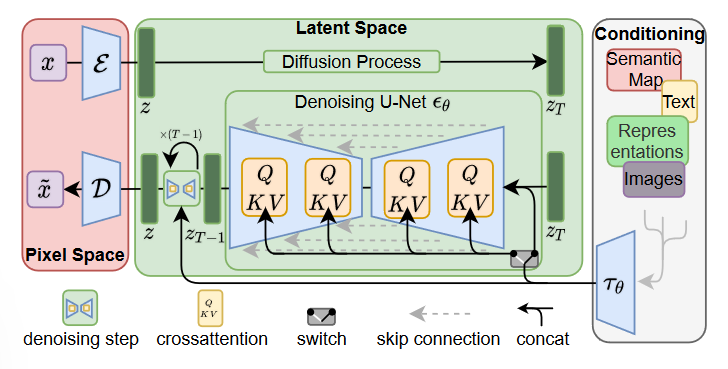
Latent Diffusion Models 2022
Stable Diffusion产品的背后模型
将图像形成过程分解为一系列去噪自编码器的顺序应用,扩散模型(DMs)在图像数据及更广泛范围内实现了最先进的合成结果。此外,它们的表达允许一种引导机制来控制图像生成过程而无需重新训练。然而,由于这些模型通常直接在像素空间中操作,优化强大的DMs通常需要消耗数百个GPU天,论文提出的方法将它们在latent space中进行并使用预训练的autoencoder.并使用了cross-attention结构,现在看来也是非常经典了.

- $$
- \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^{T}}{\sqrt{d}}\right)\cdot V\
- Q=W_Q^{(i)}\cdot\varphi_i(z_t),K=W_K^{(i)}\cdot\tau_\theta(y),V=W_V^{(i)}\cdot\tau_\theta(y)
- $$
$$
L_{DM}=\mathbb{E}{x,\epsilon\sim\mathcal{N}(0,1),t}\Big[|\epsilon-\epsilon\theta(x_t,t)|_2^2\Big] \
L_{LDM}:=\mathbb{E}{\mathcal{E}(x),y,\epsilon\sim\mathcal{N}(0,1),t}\Big[|\epsilon-\epsilon\theta(z_t,t,\tau_\theta(y))|_2^2\Big]$$
CLIP 2021
OpenAI用于DALLE的文字与图像匹配 利用不同的encoders将文字和图像联系了起来
计算机视觉系统经过训练可以预测一组固定的预定对象类别。这种受限的监督形式限制了其通用性和可用性,因为要指定任何其他视觉概念,都需要额外的标记数据。
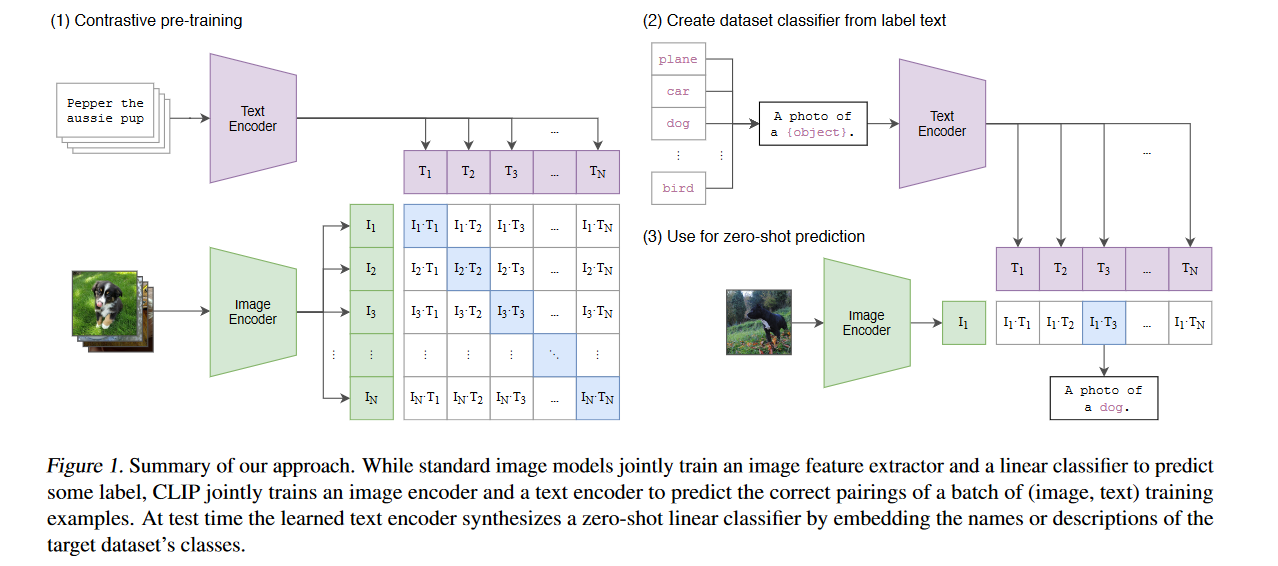
主要是解决利用文本信息监督图像,并实现zero-shot transfer.

ControlNet 2023
开创性的有价值的工作,使用pose,edge maps,segmentation map作为监督信息控制图像布局. 技术上利用微调技术并利用额外的pose等信息引导图像生成.
Adding Conditional Control to Text-to-Image Diffusion Models
随着文字到图像扩散模型的出现,我们现在只需输入文字提示,就能创作出视觉效果极佳的图像。
然而,文本到图像模型对图像空间构成的控制能力有限;仅靠文本提示很难精确表达复杂的布局、姿势、形状和形态。要生成与我们的心理想象精确匹配的图像,往往需要反复编辑提示、检查生成的图像,然后重新编辑提示。
ControlNet利用了微调技术,冻结原始块,然后使用原本的权重处理额外信息c,c通过零卷积再加回去得到$y^{c}$

为了给这样一个预训练的神经块添加一个controlnet网络,锁定(冻结)原始块的参数Θ,同时将该块克隆到一个参数为Θc的可训练拷贝
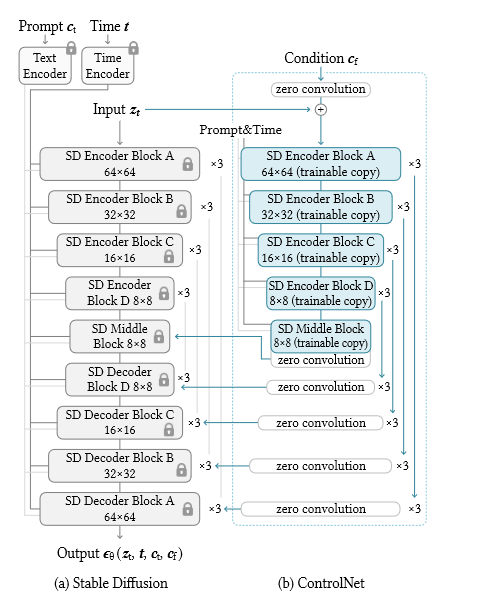
可训练副本以外部条件向量c作为输入。当这种结构应用于诸如稳定扩散( Stable Diffusion )这样的大型模型时,锁定的参数保留了用数十亿张图像训练的生产就绪模型,而可训练的副本则重用了这种大规模预训练的模型,以建立处理各种输入条件的深度、鲁棒和强大的骨干。
$$
y_{\mathfrak{c}}=\mathcal{F}(x;\Theta)+\mathcal{Z}(\mathcal{F}(x+\mathcal{Z}(c;\Theta_{\mathfrak{z}1});\Theta_{\mathfrak{c}});\Theta_{\mathfrak{z}2})
$$
训练目标
$$
\mathcal{L}=\mathbb{E}{\boldsymbol{z}_0,\boldsymbol{t},\boldsymbol{c}_t,\boldsymbol{c}\mathrm{f},\epsilon\sim\mathcal{N}(0,1)}\left[|\epsilon-\epsilon_\theta(\boldsymbol{z}t,t,\boldsymbol{c}_t,\boldsymbol{c}\mathrm{f}))|_2^2\right]$$
在训练过程中,我们用空字符串随机替换50 %的文本提示ct。这种方法增加了controlnet网络在输入条件图像(例如,边缘,姿态,深度等。)中直接识别语义的能力,作为提示的替代。在训练过程中,由于零卷积不会给网络添加噪声,所以模型应该始终能够预测高质量的图像。我们观察到,模型并没有逐步学习控制条件,而是突然成功地跟随输入条件图像;通常在小于10K的优化步数。
在inference部分介绍了CFG以及组合多个controlnet.
$$
\epsilon_{\mathrm{prd}}=\epsilon_{\mathrm{uc}}+\beta_{\mathrm{cfg}}(\epsilon_{\mathrm{c}}-\epsilon_{\mathrm{uc}})
$$
T2I-Adapter 2023
T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
大规模文本到图像( T2I )模型令人难以置信的生成能力已经显示出强大的学习复杂结构和有意义语义的能力.
Motivation:然而,仅仅依靠文本提示并不能充分地利用模型学习到的知识,尤其是需要灵活准确地控制(例如,颜色和结构)时.
具体来说,提出学习简单轻量级的T2I - Adapters来将T2I模型中的内部知识与外部控制信号对齐,同时冻结原始的大型T2I模型
在本文中探讨是否有可能通过某种方式"挖掘出" T2I模型隐含学习到的能力,特别是高层结构和语义能力,然后明确地使用它们来更精确地控制生成。作者认为一个小型的适配器模型可以达到这个目的,因为它不是学习新的生成能力,而是学习T2I模型中从控制信息到内部知识的映射。也就是说,这里的主要问题是"对齐"问题,即内部知识和外部控制信号应该对齐。
$$
\left.\left{\begin{array}{l}\mathbf{Q}=\mathbf{W}_Q\phi(\mathbf{Z}_t);\mathbf{K}=\mathbf{W}_K\tau(\mathbf{y});\mathbf{V}=\mathbf{W}_V\tau(\mathbf{y})\Attention(\mathbf{Q},\mathbf{K},\mathbf{V})=softmax(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt d})\cdot\mathbf{V}\end{array}\right.\right.
$$
$$
\mathcal{L}=\mathbb{E}{\mathbf{Z}_t,\mathbf{C},\epsilon,t}(||\epsilon-\epsilon\theta(\mathbf{Z}_t,\mathbf{C})||_2^2)
$$
C表示条件信息,θ表示UNet去噪器的函数。
在推理过程中,输入的隐映射$Z^{T}$由随机高斯分布生成。给定$Z^{T}$,$\epsilon_{\theta}$在每一步t预测一个噪声估计,条件为C。噪声特征图通过减去它变得越来越清晰.
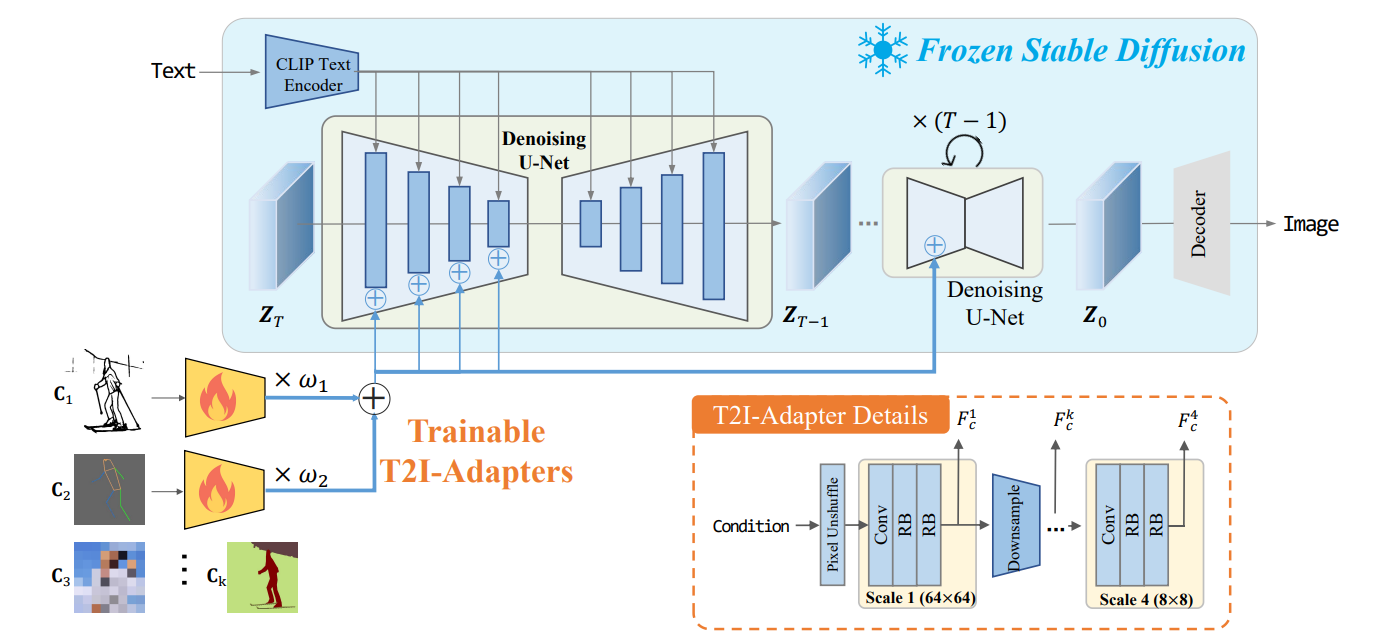
在每个尺度下,利用一个卷积层和两个残差块( RB )来提取条件特征Fck.最终形成多尺度条件特征Fc = { F$^{1}{c}$,F$^{2}{c}$,F$^{3}{c}$,F$^{4}{c}$ }。注意到Fc的维度与UNet去噪器编码器中的中间特征$F_{enc}$= { F$^{1}{enc}$,F$^{2}{enc}$,F$^{3}{enc}$,F$^{4}{enc}$ }相同,然后在每个尺度下,F$_{c}$与$F_{enc}$相加。
$$
\begin{aligned}&\mathbf{F}{c}=\mathcal{F}{AD}(\mathbf{C})\&\hat{\mathbf{F}}{enc}^{i}=\mathbf{F}{enc}^{i}+\mathbf{F}{c}^{i},i\in{1,2,3,4}\end{aligned} $$ C为条件输入。F${AD}$是T2I的适配器
除了使用单个适配器作为条件外,提出的T2I适配器还支持多种条件。注意这个策略不需要额外的训练。
$$
\mathbf{F}c=\sum{k=1}^K\omega_k\mathcal{F}_{AD}^k(\mathbf{C}_k)
$$
IP-Adapter 2023
IP-Adapter:Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
背景目的与结论:近年来,大型文本到图像扩散模型因其出色的生成能力创造出高保真度的图像而表现出强大的能力。然而,仅使用文本提示生成想要的图像是非常困难的,因为它往往涉及复杂的提示工程。文字提示的一种替代方式是图像提示,俗话说:"一张图像值一千个字"。虽然现有的从预训练模型直接微调的方法是有效的,但它们需要较大的计算资源,并且与其他基础模型、文本提示和结构控制不兼容
在本文中提出了IP - Adapter,一种有效的、轻量级的适配器,以实现预训练的文本到图像扩散模型的图像提示能力。我们的IP - Adapter的关键设计是解耦的交叉注意力机制,将文本特征和图像特征的交叉注意力层分离。
得益于解耦的交叉注意力策略,图像提示也可以很好地与文本提示协同工作,实现多模态图像生成。
也是使用图像作为提示信息的工作
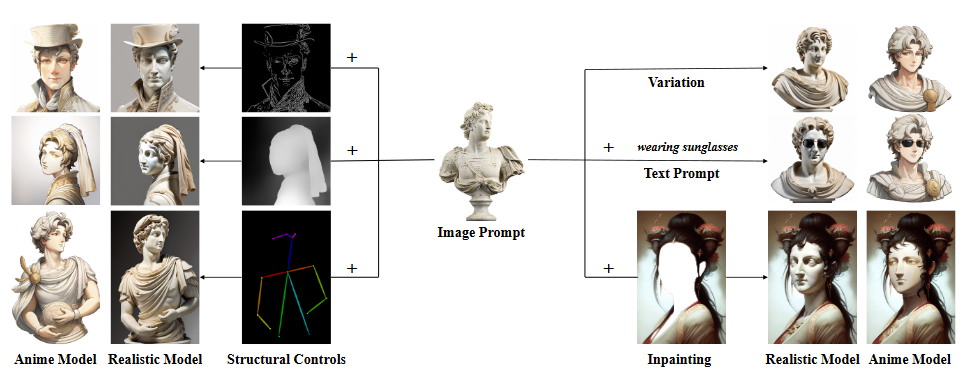
以往的工作通过替换text-encoder为image-encoder,本作强调在不修改原始模型的情况下实现图像提示功能.
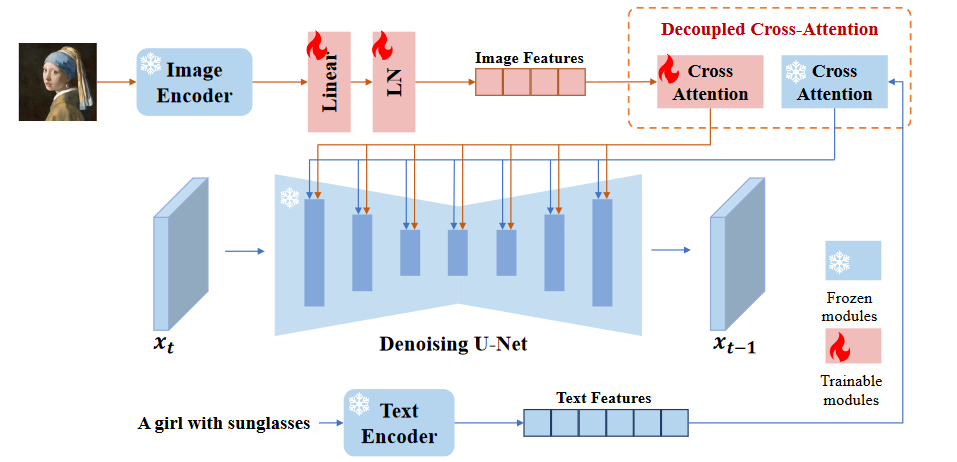
文章认为,上述方法的主要问题在于文本到图像扩散模型的交叉注意力模块.对预训练扩散模型中的交叉注意力层的key和value投影权重进行训练,使其适应文本特征.
因此,将图像特征和文本特征融合到交叉注意力层只完成了图像特征到文本特征的对齐,但这可能会遗漏一些图像特有的信息,最终导致仅与参考图像进行粗粒度可控生成(例如,图像风格)。
$$
L_{\mathrm{simple}}=\mathbb{E}{\boldsymbol{x}_0,\boldsymbol{\epsilon}\sim\mathcal{N}(\mathbf{0},\mathbf{I}),\boldsymbol{c},t}|\epsilon-\epsilon\theta(\boldsymbol{x}t,\boldsymbol{c},t)|^2 $$ 在CFG下 $$ \hat{\epsilon}\theta(x_t,c,t)=w\epsilon_\theta(x_t,c,t)+(1-w)\epsilon_\theta(x_t,t)
$$
目前的适配器很难匹配微调的图像提示模型或从零开始训练的模型的性能。主要原因是图像特征不能有效地嵌入到预训练模型中。大多数方法只是简单地将串联的特征输入到冻结的交叉注意力层中,阻止了扩散模型从图像提示中捕获细粒度的特征。为了解决这个问题,提出了一种解耦的交叉注意力策略,通过新增加的交叉注意力层来嵌入图像特征。
插入图像特征的一种直接方法是将图像特征和文本特征进行拼接,然后将其输入到交叉注意力层中.然而,我们发现这种方法的有效性不足.相反提出了一种解耦的交叉注意力机制,其中文本特征和图像特征的交叉注意力层是分开的。
$$
\mathbf{Z}''=\text{Attention}(\mathbf{Q},\mathbf{K}',\mathbf{V}')=\text{Softmax}(\frac{\mathbf{Q}(\mathbf{K}')^\top}{\sqrt{d}})\mathbf{V}'
$$
$$
\mathbf{Z}^{new}=\mathrm{Softmax}(\frac{\mathbf{Q}\mathbf{K}^{\top}}{\sqrt{d}})\mathbf{V}+\mathrm{Softmax}(\frac{\mathbf{Q}(\mathbf{K}^{\prime})^{\top}}{\sqrt{d}})\mathbf{V}^{\prime}\\mathrm{where~}\mathbf{Q}=\mathbf{Z}\mathbf{W}_q,\mathbf{K}=c_t\mathbf{W}_k,\mathbf{V}=c_t\mathbf{W}_v,\mathbf{K}^{\prime}=c_i\mathbf{W}_k^{\prime},\mathbf{V}^{\prime}=c_i\mathbf{W}_v^{\prime}
$$
由于冻结了原始的UNet模型,在上述解耦的交叉注意力中,只有W′k和W′v是可训练的.
$$
L_{\mathrm{simple}}=\mathbb{E}{\boldsymbol{x}_0,\boldsymbol{\epsilon},\boldsymbol{c}_t,\boldsymbol{c}_i,t}|\epsilon-\epsilon\theta(x_t,c_t,c_i,t)|^2 \
\hat{\epsilon}\theta(x_t,c_t,c_i,t)=w\epsilon\theta(x_t,c_t,c_i,t)+(1-w)\epsilon_\theta(x_t,t)
$$
我们还在训练阶段随机丢弃图像条件,以便在推理阶段实现无分类器指导.
由于文本交叉注意力和图像交叉注意力是分离的,我们还可以在推断阶段调整图像条件的权重
$$
\mathbf{Z}^{new}=\text{Attention}(\mathbf{Q},\mathbf{K},\mathbf{V})+\lambda\cdot\text{Attention}(\mathbf{Q},\mathbf{K}',\mathbf{V}')
$$
为了训练IP - Adapter,从两个开源数据集LAION - 2B和COYO - 700M中构建了一个包含约1000万个文本-图像对的多模态数据集
InstantID 2024
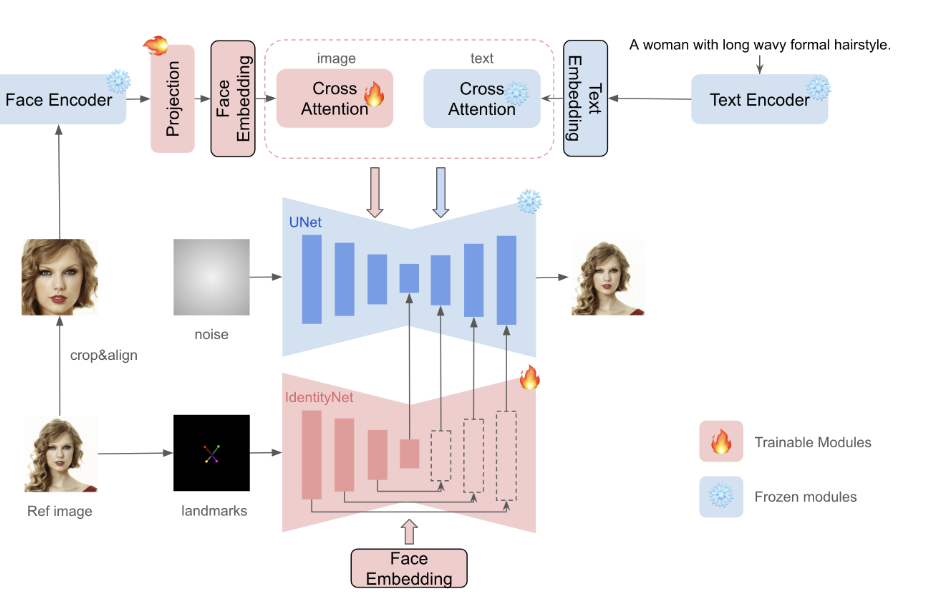
利用Textual Inversion、DreamBooth、LoRA等方法进行个性化图像合成已经取得了显著的进展。然而,它们的实际应用受到高存储需求、长时间微调过程以及需要多个参考图像的限制。相反,现有的基于ID嵌入的方法,虽然只需要单一的前向推断,但面临挑战:它们要么需要在众多模型参数之间进行广泛的微调,缺乏与社区预训练模型的兼容性,要么不能保持高的人脸保真度
我InstantID,这是一个的基于扩散模型的解决方案,即插即用模块只使用一张人脸图像就能很好地处理各种风格的图像个性化,同时保证了高保真度。
为了实现这一点,设计了一个新颖的IdentityNet,通过强语义和弱空间条件,将面部和地标图像与文本提示相结合,以引导图像生成.
生成精确保留人类主体错综复杂的身份细节的定制图像。
它包含三个关键部分:( 1 )能够捕获鲁棒语义人脸信息的ID嵌入;( 2 )一个轻量级的自适应模块,具有解耦的交叉注意力,便于使用图像作为视觉提示;( 3 )提出了一种基于额外空间控制的编码参考人脸图像细节特征的IdentityNet。
首先采用人脸编码器代替CLIP提取语义人脸特征,并使用可训练的投影层将其投影到文本特征空间.
然后,引入解耦交叉注意力的轻量级自适应模块,以支持图像作为提示。
在IdentityNet中,生成过程完全由人脸嵌入引导,无需任何文本信息.只更新新增加的模块,而预训练的文本到图像模型保持冻结,以确保灵活性.
在训练过程中,只对Image Adapter和Identity Net的参数进行优化,而对预训练的扩散模型的参数保持冻结。我们在具有人类主题的图像-文本对上训练整个InstantID流水线,采用了类似于原始稳定扩散工作中使用的训练目标
$$
\mathcal{L}=\mathbb{E}{z_t,t,C,C_i,\epsilon\sim\mathcal{N}(0,1)}[|\epsilon-\epsilon\theta(z_t,t,C,C_i)|_2^2]$$
$C_{i}$为IdentityNet上的任务特定图像条件。值得注意的是,在训练过程中,我们不会随意丢弃文本或图片条件,因为我们已经去掉了IdentityNet中的文本提示条件。
上面四篇工作都是类似的,利用额外控制信息和改进一些模型进行微调使得捕获输入的图像.下面几篇工作是OPenAI与Google的文生图模型,已经作为产品级模型.
GLIDE 2021
GLIDE能够根据自然语言描述生成图像,这意味着用户可以用文本提示来生成相应的视觉内容。
论文比较了两种引导扩散模型的技术——CLIP引导和无分类器引导(classifier-free guidance)。研究发现,无分类器引导在照片真实感和标题相似性方面更受人类评估者的青睐。GLIDE不仅能够进行零样本(zero-shot)图像生成,还能通过图像修复(inpainting)进行细粒度的图像编辑,使得用户可以迭代改进模型样本以匹配更复杂的文本提示。
Ho & Salimans 提出了无分类器引导,一种用于引导扩散模型的技术,它不需要单独的分类器模型来进行训练。对于无分类器指导,在训练过程中,类条件扩散模型θ ( xt | y )中的标签y被一个固定概率的零标签∑所代替。为了用通用文本提示实现无分类器的指导,我们有时在训练过程中用空序列(其中,我们也称之为:)替换文本。
$$
\hat{\epsilon}\theta(x_t|c)=\epsilon\theta(x_t|\emptyset)+s\cdot(\epsilon_\theta(x_t|c)-\epsilon_\theta(x_t|\emptyset))
$$
DALLE2 2022
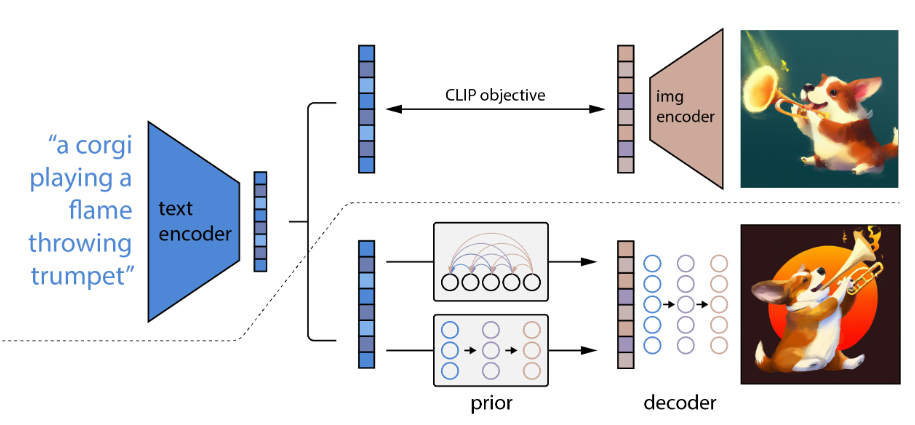
像CLIP这样的对比模型已经被证明可以学习到同时捕获语义和风格的图像的鲁棒表示。
为了利用这些表示进行图像生成,文中提出了一个两阶段模型:一个先验生成给定文本描述的CLIP图像嵌入,一个解码器生成以图像嵌入为条件的图像。
我们证明了显式地生成图像表示以最小的损失在照片真实性和字幕相似性中提高了图像的多样性。我们的解码器在图像表示的条件下也可以产生图像的变化,以保留其语义和风格,同时改变图像表示中不存在的非基本细节。此外,CLIP的联合嵌入空间可以在a z中实现语言引导的图像操作
Imagen 2022
我们提出了Imagen,我们的关键发现是,通用的大语言模型(如:T5 ),在纯文本语料上进行预训练,在编码图像合成的文本时取得了惊人的效果:增加Imagen中语言模型的大小比增加图像扩散模型的大小更能提高样本保真度和图像文本对齐度。Imagen在COCO数据集上取得了7.27的最新FID得分,而没有对COCO进行过训练,人类评分员发现Imagen样本处于标准状态
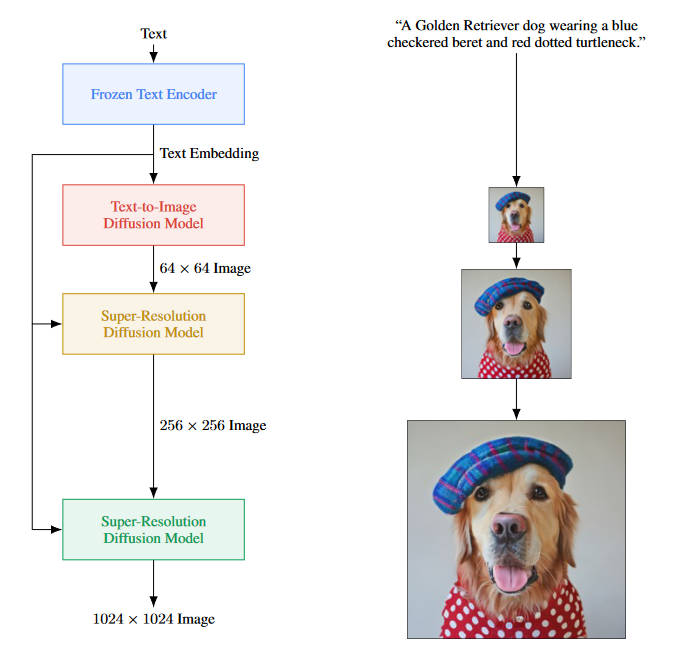
Imagen使用冻结的文本编码器将输入文本编码成文本嵌入。条件扩散模型将文本嵌入映射成一个64×64的图像。Imagen进一步利用文本条件的超分辨率扩散模型对图像进行上采样,先是64×64→256×256,然后是256×256→1024×1024。
基模型采用IPPDMU - Net架构,用于我们的64 × 64文本到图像扩散模型。该网络通过池化嵌入向量对文本嵌入进行条件化,并加入类嵌入条件化方法的扩散时间步嵌入。我们进一步通过在多个分辨率的文本嵌入上添加交叉注意力来限定整个文本嵌入序列。
超分辨率模型:对于64 × 64→256 × 256的超分辨率,采用改编自PPDMU的U - Net模型。为了提高内存效率、推理时间和收敛速度(我们的变体比文献[ 40,58 ]中使用的U - Net快2 - 3倍步数/秒),我们对该U - Net模型进行了多次修改。我们称这种变体为Efficient U-Net
总结一下,关于DDPM的论文本身的数学理论还是挺强的,而相关的CLIP,Adapter作为某种辅助改进既是一种创新型的工作也很有价值,理论性研究起来也没有那么困难,这种工作做起来还是很舒服的.
Comments NOTHING