使用keras构建
GAN理论
GAN(Generative Adversarial Networks,生成式对抗网络)由 Goodfellow 等人于 2014 年提出,它能够迫使网络生成的合成图像与真实图像在统计上几乎无法区分,从而获得相当逼真的合成图像。
GAN 由以下两部分组成:
- 生成器网络(Generator Network):它以一个随机向量作为输入,并将其解码为一张合成图像。
- 判别器网络(Discriminator Network):以一张图像作为输入,并预测该图像是来自训练集的真实图像还是由生成器网络生成的合成图像
想象一名伪造者试图伪造一副毕加索的画作。一开始,伪造者非常不擅长这项任务。他将自己的一些赝品与毕加索真迹混在一起,并将其展示给一位艺术商人。艺术商人对每幅画进行真实性评估,并向伪造者给出反馈,告诉他是什么让毕加索作品看起来像一幅毕加索作品。伪造者回到自己的工作室,并准备一些新的赝品。随着时间的推移,伪造者变得越来越擅长模仿毕加索的风格,艺术商人也变得越来越擅长找出赝品。最后,他们手上拥有了一些优秀的毕加索赝品。

- 一开始,我们手头上只有真实图像,生成器首先根据潜在空间中的随机向量生成第一批合成图像,由于没有参照物,得到的图像很糟糕。
- 接着,将合成图像的标签设为 0,真实图像的标签设为 1,混合后输入到判别器中。这时判别器就像一个二元分类器,它输出每张图像为真实图像的概率,使得输入真实图像时,输出向 1 靠近,输入合成图像时,输出向 0 靠近,由此形成一个判别标准。
- 然后,训练生成器,根据判别器的训练反馈结果更新参数,训练生成器网络的目的是使其能够欺骗判别器网络,因此随着训练的进行,它能够逐渐生成越来越逼真的图像,即看起来与真实图像无法区分的人造图像,以至于判别器网络无法区分二者。与此同时,判别器也在不断适应生成器逐渐提高的能力,使得其判别真假图像的能力愈来愈高。
- 一旦训练结束,在最理想的状态下,生成器就能够生成十分逼真的合成图像,使得判别器无法辨别真实图像和合成图像的差别。
开始
本节分步实现一个最原始的 GAN,并使用 MNIST 手写数字数据集中的图像作为真实图像,在 GAN 上合成手写数字图像。
生成器
img_rows = 28
img_cols = 28
channels = 1
img_shape = (img_rows, img_cols, channels)
latent_dim = 100
generator_input = Input(shape=(latent_dim,))
# model
x = Dense(256)(generator_input)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(momentum=0.8)(x)
x = Dense(512)(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(momentum=0.8)(x)
x = Dense(1024)(x)
x = LeakyReLU(alpha=0.2)(x)
x = BatchNormalization(momentum=0.8)(x)
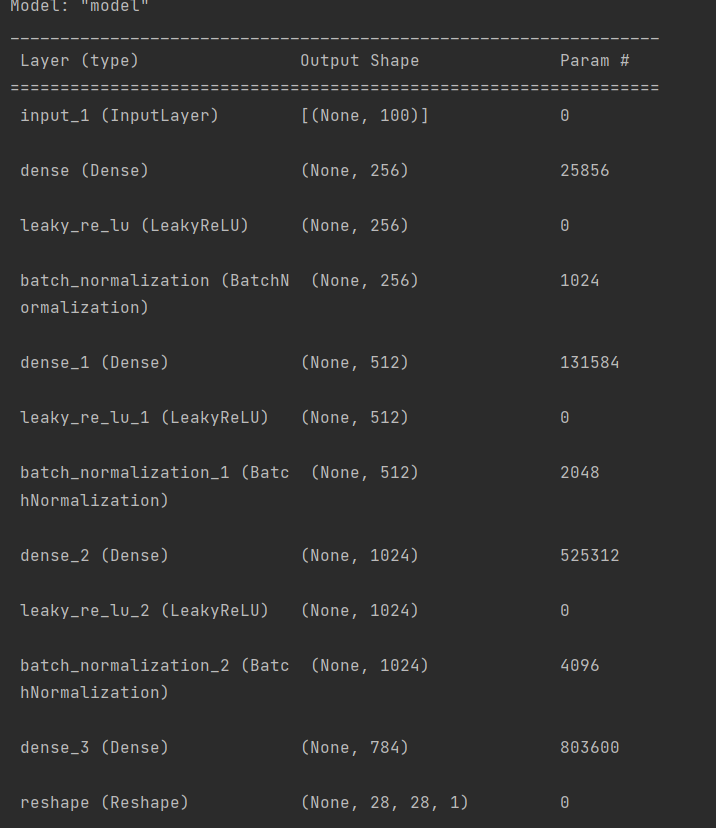
x = Dense(np.prod(img_shape), activation='tanh')(x)
x = Reshape(img_shape)(x)
generator = Model(generator_input,x)
print(generator.summary())上面是一个生成器,可以看到我们尝试输入一个大小为100向量,输出为28x28x1的矩阵.即单通道28x28的图像.
判别器
discriminator_input = Input(shape=img_shape)
x = Flatten()(discriminator_input)
x = Dense(512)(x)
x = LeakyReLU(alpha=0.2)(x)
x = Dense(256)(x)
x = LeakyReLU(alpha=0.2)(x)
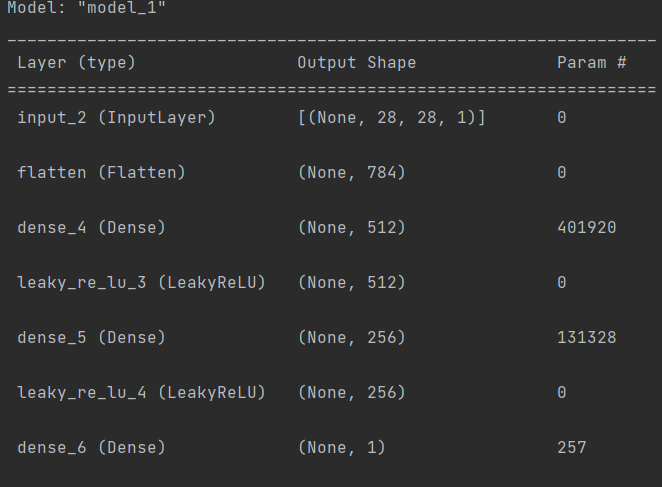
x = Dense(1,activation='sigmoid')(x)
discriminator = Model(discriminator_input,x)
print(discriminator.summary())输入时MINIST数据集的数据,中间都是全连接层,加的leakyrelu激活函数.注意最后输出一个值,表示是不是真的图像,如果大则表示相近.
编译判别器网络
discriminator.compile(loss='binary_crossentropy',
optimizer='adam',metrics=['accuracy'])构建GAN
gan_input = Input(shape=(latent_dim,))
generator_image = generator(gan_input)
discriminator.trainable = False
gan_output = discriminator(generator_image)
gan = Model(gan_input,gan_output)
gan.compile(loss='binary_crossentropy',optimizer='adam')
print(gan.summary())编译GAN
gan.compile(loss='binary_crossentropy',
optimizer='adam')- 从潜在空间中抽取随机的点,即随机噪声。
- 利用这些随机噪声通过生成器生成图像。
- 将生成的合成图像与真实图像混合。
- 使用这些混合后的图像以及相应的标签(真实图像为「1」,合成图像为「0」)来训练判别器。
- 在潜在空间中随机抽取新的点。
- 使用这些新的随机向量以及全部是「1」的标签训练 GAN。由于此时已经在 GAN 模型中冻结了判别器,故只会更新生成器的权重,其更新方向是使得判别器能够将合成图像预测为「真实图像」。这个过程就是训练生成器去欺骗判别器。
导入数据
from tensorflow.keras.datasets import mnist
(X_train, _), (_, _) = mnist.load_data()数据标准化,将每张图像的每个像素值都缩放到 -1 至 1 之间,有利于模型学习与训练。
X_train = X_train / 127.5 - 1.由于数据是6000*28*28,缺少一个维度,我们需要28*28*1
X_train = np.expand_dims(X_train, axis=3)接下来开始训练
epochs = 1000
batch_size = 128
# 标签 label
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epochs in range(epochs):
# 训练判别器
# 随机选一个batch的照片
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# 生成噪音(一般正态分布)
noise = np.random.normal(0, 1, (batch_size, latent_dim))
# 根据噪音生成图片
gen_imgs = generator.predict(noise)
d_loss_real = discriminator.train_on_batch(imgs, valid)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_fake, d_loss_real)
# 使用这些随机向量以及全部是「1」的标签
# 通过 GAN 模型训练生成器(此时判别器权重已被冻结)
noise = np.random.normal(0, 1, (batch_size, latent_dim))
g_loss = gan.train_on_batch(noise, valid)
if epochs % 200 == 0:
# 打印出判别器的损失值 loss 和 准确率 acc,及生成器的 loss
print("%d [D loss:%f,acc:%.2f%%][G loss:%f]" % (epochs, d_loss[0], 100 * d_loss[1], g_loss))
gen_imgs = 0.5 * gen_imgs + 0.5
_, axs = plt.subplots(5, 5)
cnt = 0
for i in range(5):
for j in range(5):
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].axis('off')
cnt += 1
plt.show()
plt.close()
# _, axs = plt.subplots(5, 5)
# cnt = 0
# for i in range(5):
# for j in range(5):
# axs[i, j].imshow(X_train[cnt, :, :, 0], cmap='gray')
# axs[i, j].axis('off')
# cnt += 1
# plt.show()
# plt.close()结果




貌似最终效果一般,但能看到每次的变化
details
当discriminator被compile之后,即使设置了discriminator.trainable=False,该discriminator仍然可以通过train_on_batch的方式被训练;
但是如果discriminator在被compile之前就把训练状态设置为False,那么即使是使用discriminator.train_on_batch的方式也不能训练该判别器。
当compile一个模型时,该模型的训练状态就被固定成当前状态了(比如discriminator.trainable=True);
当尝试修改compile之后的discriminator的训练状态时,实质上是对另外一个discriminator的训练状态进行修改(也许接下来会compile);
由于框架自身的机制,上面compile之后的两个discriminator拥有相同的网络权重(即使它们被看作是两个独立的模型)
DCGAN
普通的GAN训练效果挺差的.
DCGAN(深度卷积生成对抗网络,Deep Convolution Generative Adversarial Network)基于 GAN 做了网络结构的改进,将 卷积神经网络 应用在生成器网络和判别器网络中,使得整个模型具有更好的训练稳定性和性能表现。其工作原理和 GAN 相同,这里不再赘述
生成器网络结构
鉴别器网络结构
DCGAN 是一类模型的总称,其结构特点如下所示:
- 所有的池化层使用步幅卷积和 微步幅卷积 Fractionally Strided Convolution 或 上采样 进行替换,步幅卷积指的是卷积层的步长
strides>1。 - 判别器网络中使用步幅卷积,目的是进行图像压缩;生成器网路中使用微步幅卷积或上采样,目的是进行图像放大。
- 在生成器网络和判别器网络中使用批标准化。
- 对于更深的构架去掉 Dense 全连接层。
- 生成器网络中输出层使用 Tanh 激活函数,其他所有的层都使用 [ReLu](https://baike.baidu.com/item/ReLU 函数/22689567?fr=aladdin) 激活函数。
- 判别器网络中所有的层使用 LeakyReLu 激活函数
这里写一下明显差别
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, Reshape
from tensorflow.keras.layers import UpSampling2D
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import BatchNormalization, Activation
from tensorflow.keras.models import Model
# 生成器
img_rows = 28
img_cols = 28
channels = 1
img_shape = (img_rows, img_cols, channels)
latent_dim = 100
generator_input = Input(shape=(latent_dim,))
x = Dense(128 * 7 * 7, activation="relu",)(generator_input)
x = Reshape((7, 7, 128))(x)
x = UpSampling2D()(x)
x = Conv2D(128, kernel_size=3, padding='same')(x)
x = BatchNormalization(momentum=0.8)(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2D(64, 3, padding='same')(x)
x = BatchNormalization(momentum=0.8)(x)
x = Activation("relu")(x)
x = Conv2D(channels, kernel_size=3, activation='tanh', padding='same')(x)
generator = Model(generator_input, x)# 构建判别器
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten, ZeroPadding2D
from tensorflow.keras.optimizers import Adam
discriminator_input = Input(shape=img_shape)
x = Conv2D(32, kernel_size=3, strides=2, padding="same")(discriminator_input)
x = LeakyReLU(alpha=0.2)(x)
x = Dropout(0.25)(x)
x = Conv2D(64, kernel_size=3, strides=2, padding="same")(x)
x = ZeroPadding2D(padding=((0, 1), (0, 1)))(x)
x = BatchNormalization(momentum=0.8)(x)
x = LeakyReLU(alpha=0.2)(x)
x = Dropout(0.25)(x)
x = Conv2D(128, kernel_size=3, strides=2, padding="same")(x)
x = BatchNormalization(momentum=0.8)(x)
x = LeakyReLU(alpha=0.2)(x)
x = Dropout(0.25)(x)
x = Conv2D(256, kernel_size=3, strides=1, padding="same")(x)
x = BatchNormalization(momentum=0.8)(x)
x = LeakyReLU(alpha=0.2)(x)
x = Dropout(0.25)(x)
x = Flatten()(x)
x = Dense(1, activation='sigmoid')(x)
discriminator = Model(discriminator_input, x)
# 实例化 Adam 优化器
optimizer = Adam(0.0002, 0.5)
# 编译模型
discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])其他的都类似.
训练DCGAN的技巧
- 使用正态分布(高斯分布)对潜在空间中的点进行采样,而不用均匀分布。
- 随机性能够提高稳健性。训练 GAN 得到的是一个动态平衡,所以 GAN 可能以各种方式“卡住”。在训练过程中引入随机性有助于防止出现这种情况。可通过两种方式引入随机性:一种是在判别器中使用 Dropout,另一种是向判别器的标签添加随机噪声。
- 稀疏的梯度会妨碍 GAN 的训练。最大池化运算和 ReLU 激活函数都可能导致梯度稀疏。故本次实验在判别器网络中使用步幅卷积代替 最大池化,使用 LeakyReLU 层来代替 ReLU。
参考资料
李宏毅 机器学习
deep learning 吴恩达
Comments NOTHING