最近大语言模型实在太火了,创造了一批的上层应用,对于普通人来说其实很难去训练一个大模型,顶多去微调一下.
在线的GPT服务有很多,我个人推荐Poe,支持许多模型并允许自己上传一些微调后的模型,另外有些模型可能不在Poe中,可以去它们的官网使用.
使用在线服务可能带来两个问题:
- 数据安全和隐私
- 内容审查
除了这种调用API或者web app模式之外,其实在本地运行一些大模型已经可以很好使用了,这里找到了一篇英文博客Six Ways of Running Large Language Models (LLMs) Locally (January 2024) (kleiber.me).
介绍一些本地使用大语言模型的方法.
llama.cpp
使用c++来做inference,相比于Python节省内存以及提升运行速度.
这也是其他许多本地运行大模型的应用的底层. 使得只需要CPU就能使用大模型.
作为一个用户,并不需要使用这个库.本身支持许多模型的推理.

此外也提供了其它语言的binding
Transformers
使用HuggingFace提供的API(transformers)访问存储在Hugging Face Hub中的模型,这种也是属于编程方式,适合进行微调模型.因为Hugging Face也提供了许多微调的API,比如PEFT.
from huggingface_hub import snapshot_download
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
HF_MODEL = 'lmsys/fastchat-t5-3b-v1.0'
HF_MODEL_PATH = HF_MODEL.split('/')[1]
# Download the model from the Hugging Face Hub
# Alternatively: git lfs install && git clone https://huggingface.co/lmsys/fastchat-t5-3b-v1.0
snapshot_download(HF_MODEL, local_dir=HF_MODEL_PATH)
# Create the pipeline
tokenizer = AutoTokenizer.from_pretrained(HF_MODEL_PATH, legacy=False)
model = AutoModelForSeq2SeqLM.from_pretrained(HF_MODEL_PATH)
pipeline = pipeline('text2text-generation', model=model, tokenizer=tokenizer, max_new_tokens=100)
# Run inference
result = pipeline('Tell a joke about LLMs.')
print(result[0]['generated_text'])vLLM
也是一个库,vLLM 支持许多常见的 HuggingFace 模型,并能为与 OpenAI 兼容的 API 服务器提供服务
from vllm import LLM
llm = LLM(model='facebook/opt-125m')
output = llm.generate('Tell a joke about LLMs.')
print(output)from vllm import LLM, SamplingParams
prompts = [
'Tell a joke about LLMs.',
]
sampling_params = SamplingParams(temperature=0.75, top_p=0.95)
llm = LLM(model='facebook/opt-125m')
outputs = llm.generate(prompts, sampling_params)
print(outputs[0].prompt)
print(outputs[0].outputs[0].text)上面两个都是面向开发者的,如果只是简单的使用,可以看看下面三个工具.
Ollama
Ollama支持许多开源模型,但是测试之后发现参数量少一点的大模型表现真的不太好. 比如llama2:7B.

可以使用命令行提问.
也可以发送请求
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt":"Why is the sky blue?"
}'也有webui提供支持open-webui/open-webui: User-friendly WebUI for LLMs (Formerly Ollama WebUI) (github.com)
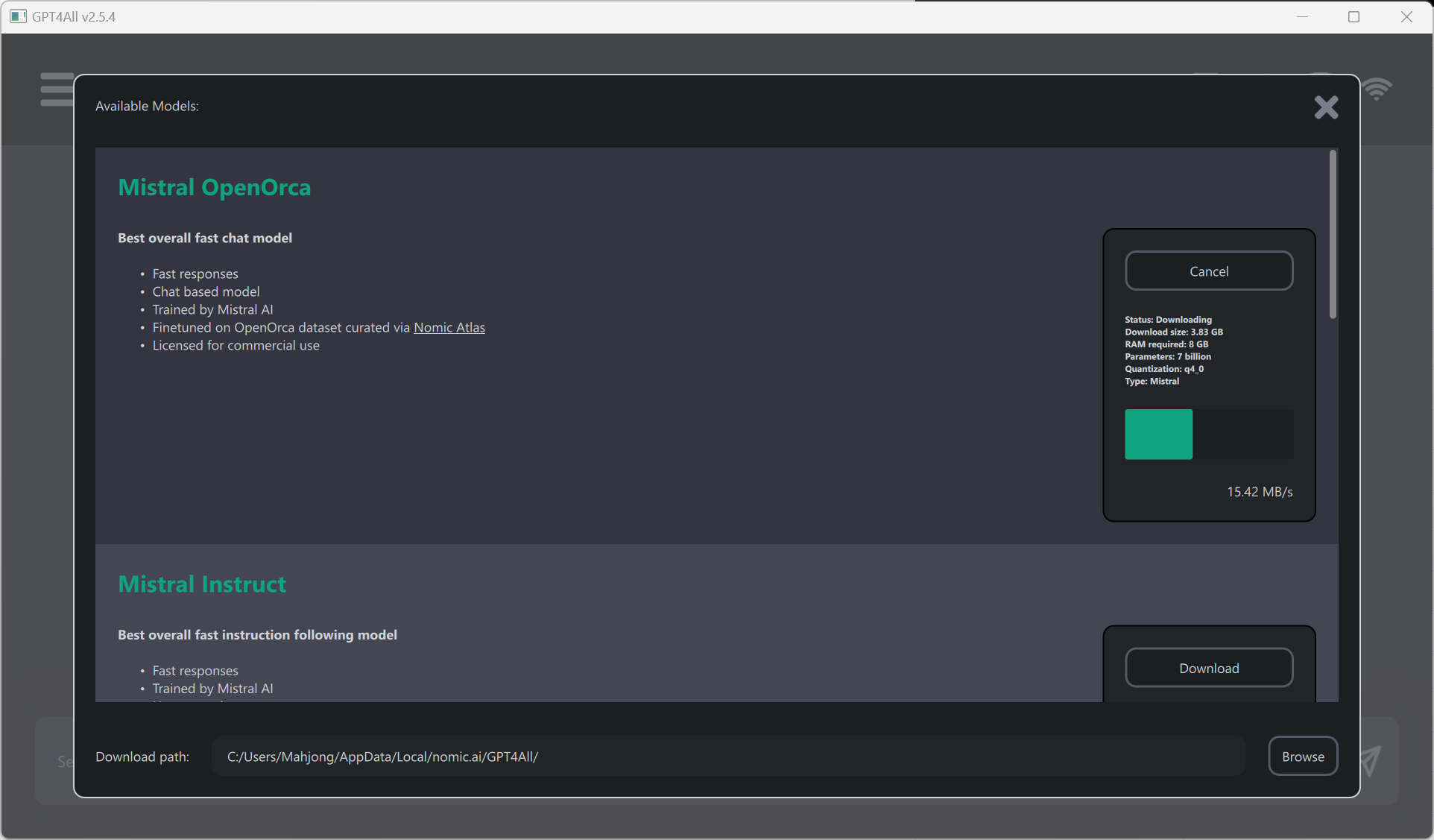
GPT4All
GPT4All GPT4All既是一系列模型,也是一个用于训练和部署模型的生态系统.与ollama类似但是更加全面,支持的模型多也自带Web UI.
| Model | BoolQ | PIQA | HellaSwag | WinoGrande | ARC-e | ARC-c | OBQA | Avg |
|---|---|---|---|---|---|---|---|---|
| GPT4All-J 6B v1.0 | 73.4 | 74.8 | 63.4 | 64.7 | 54.9 | 36 | 40.2 | 58.2 |
| GPT4All-J v1.1-breezy | 74 | 75.1 | 63.2 | 63.6 | 55.4 | 34.9 | 38.4 | 57.8 |
| GPT4All-J v1.2-jazzy | 74.8 | 74.9 | 63.6 | 63.8 | 56.6 | 35.3 | 41 | 58.6 |
| GPT4All-J v1.3-groovy | 73.6 | 74.3 | 63.8 | 63.5 | 57.7 | 35 | 38.8 | 58.1 |
| GPT4All-J Lora 6B | 68.6 | 75.8 | 66.2 | 63.5 | 56.4 | 35.7 | 40.2 | 58.1 |
| GPT4All LLaMa Lora 7B | 73.1 | 77.6 | 72.1 | 67.8 | 51.1 | 40.4 | 40.2 | 60.3 |
| GPT4All 13B snoozy | 83.3 | 79.2 | 75 | 71.3 | 60.9 | 44.2 | 43.4 | 65.3 |
| GPT4All Falcon | 77.6 | 79.8 | 74.9 | 70.1 | 67.9 | 43.4 | 42.6 | 65.2 |
| Nous-Hermes | 79.5 | 78.9 | 80 | 71.9 | 74.2 | 50.9 | 46.4 | 68.8 |
| Nous-Hermes2 | 83.9 | 80.7 | 80.1 | 71.3 | 75.7 | 52.1 | 46.2 | 70.0 |
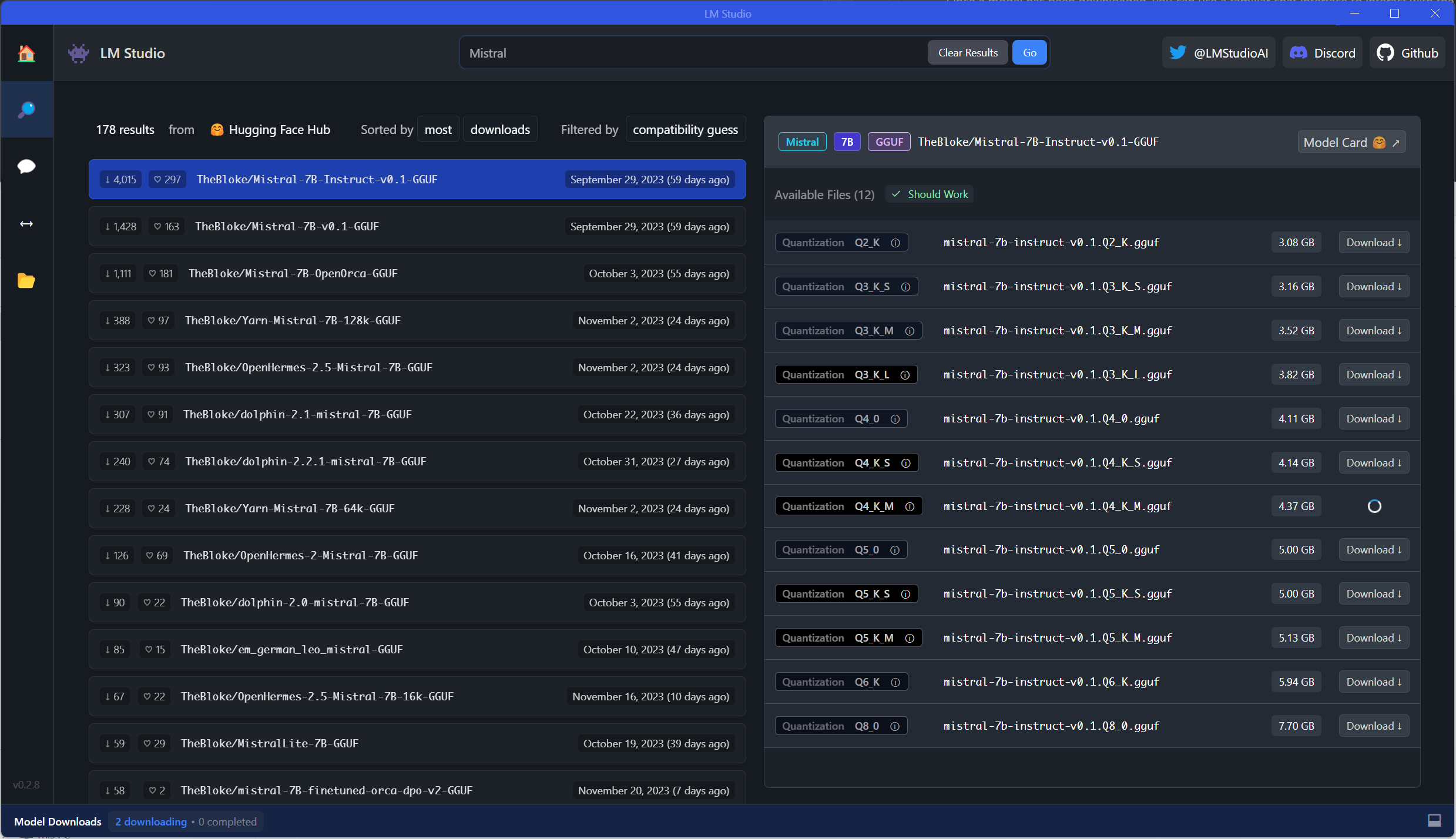
LM Studio
LM Studio - Discover, download, and run local LLMs类似GPT4All,界面看起来更复杂
也可以发送请求
curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{ "role": "system", "content": "You are a helpful coding assistant." },
{ "role": "user", "content": "How do I init and update a git submodule?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}'总结
就目前而言, Ollama或者GPT4All是绝对够用的,上面三个工具选择一个即可. 如果想要在服务器上提供API也是不错的.
Comments NOTHING